Running remote host Weka experiments
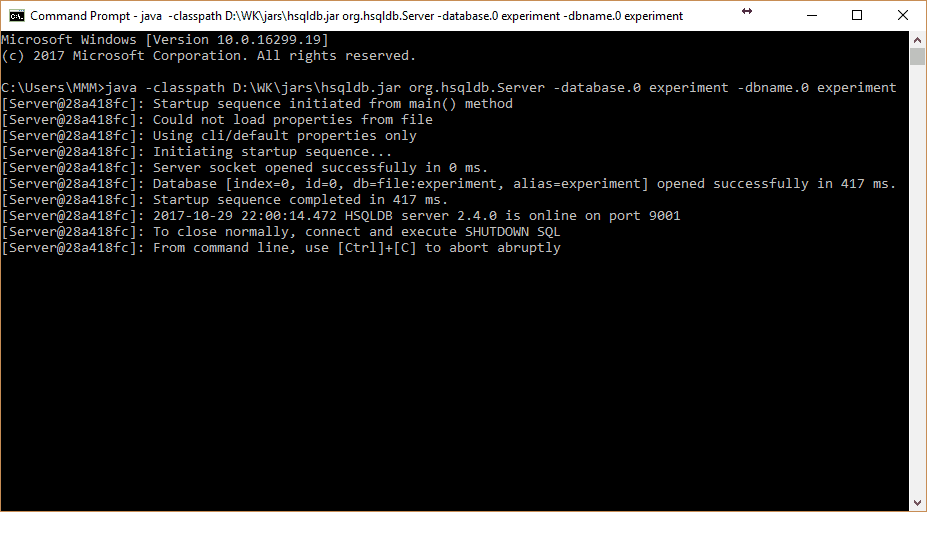
Previously, we tried to run a weka server to utilize all cores of the processor in classification tasks. But it appears that the weka server works only in explorer for classification routines. For more advanced machine learning, there is a more flexible tool – experimenter. Weka server doesn’t support this area. So what to do if you want more performance or utilize the multi-core processor of the local machine. There is a way out, but it is quite tricky. Weka has the ability to perform remote experiments that allow spreading the load across multiple host machines that have Weka set up. You can read the documentation of remote experiments here, but it may be somewhat confusing. It took time for me to figure out some parts by trial and error. The trickiest part is to set everything up and prepare the necessary command to be run before performing a remote experiment. So let’s get to it.