
Currently, WEKA is one of the most favorites machine learning tools. Without programming skills, you can do severe classification, clustering, and extensive data analysis. For some time, I’ve been using its standard GUI features without thinking much about performance bottlenecks. But since research are becoming more complex by using ensemble, voting, and other meta-algorithms that generally are based on multiple classifiers running simultaneously, the performance issues start becoming annoying. You need to wait for hours until the task is completed. The problem is that when running classification algorithms from the WEKA GUI, they utilize a single core of your processor. Such algorithms as Multi-layer Perceptron running 10-fold cross-validation is calculating one cross-fold at the time on one core, taking a long time to accomplish:
So I started looking for options to make it use all cores of the processor as separate threads for each operation fold. There are a couple of options available to do so. One is to use WekaServer package, and another is remote host processing. This time we will focus on WekaServer solution. The idea is to start a WEKA server as a distributed execution environment. When starting the server, you can indicate how many cores you want to use in your tasks—execution tasks you can monitor via a simple web interface. WekaServer isn’t a new thing, but its development as WEKA branch has been released with WEKA 3.7.5.
The key features of WekaServer:
- General purpose task executors
- A cluster can be made by having a server register with a master server as a “slave.”
- a server can be both a master and a slave
- simple load balancing
- server-side scheduling of tasks
- Tasks are saved to disk pre and post-execution
- tasks can return a result object
- Clients can talk to just one master for task submission, access to results, status, and log info regardless of where a given task gets executed
- GUI Knowledge Flow perspective and command-line interface for remote execution/scheduling of Knowledge Flow processes
- Explorer plugin allowing distributed cross-validation (each fold is a separate task), train/test split, etc., of a classifier
I think WekaServer is an excellent solution that should be included in to package itself and developed to support more features.
Starting WekaServer
Installing and starting WekaServer is relatively easy. First of all, you need to install WekaServer plugin, which can be accessed from Weka GUI Chooser. Go to Tools – > Package Manager, and in package window, you need to select wekaserver to install:
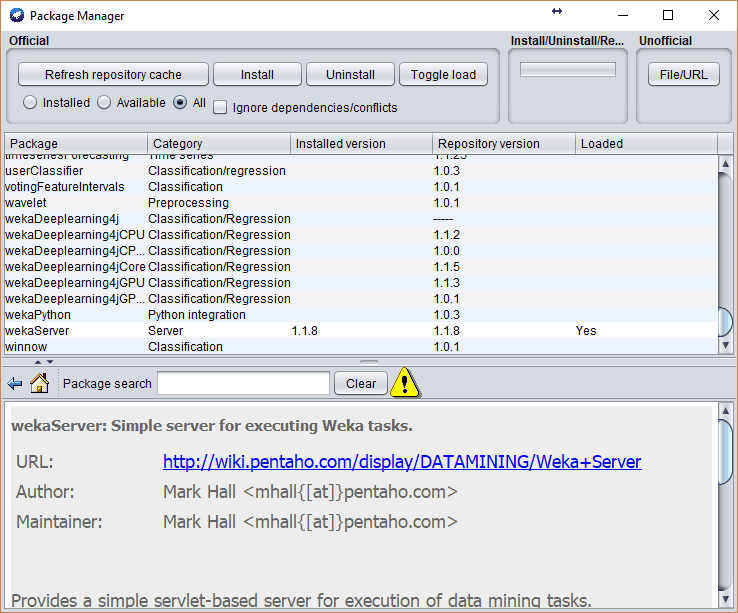
After it is downloaded and installed you need to run the server so you can send tasks to it. As web server documentation states, you need to execute weka.run WekaServer command in the console or command line. Since I am using Windows 10 it can be started from the command prompt or WEKA Simple CLI (Command Line Interface). For a non-java user like me, it may be somewhat tricky to get it running, as provided examples don’t run as expected. So the simplest way to start weka server is to run from a simple CLI interface.
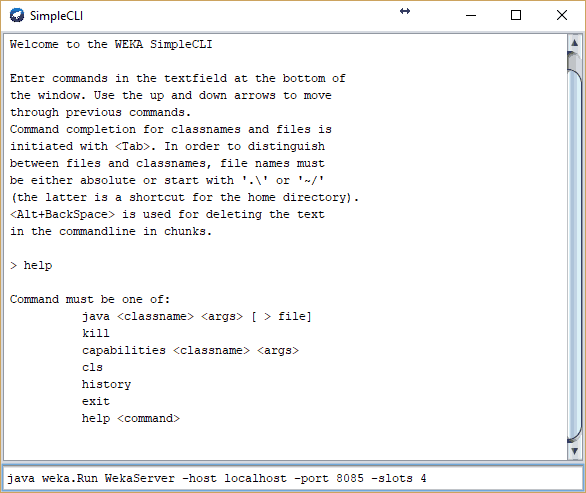
The command is:
java weka.Run WekaServer -host localhost -port 8085 -slots 4
normally used port is 8085, -slots parameter means that four cores/threads will be used.
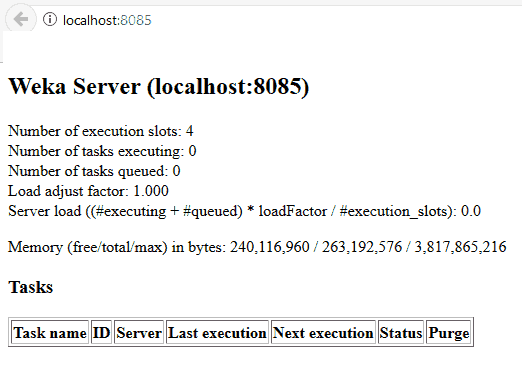
To make sure that a server has been started, in WEB browser, you need to load “https://localhost:8085/,” where you will see server status:
Running classification algorithm in WekaServer
Once you have WekaServer up and running, you can start using it for classification tasks. The simplest way is to go to Weka Explorer, where you set up your experiment, but instead of clicking the Start button, you need to select Run on server button. After you click it a dialog box opens where you need to enter the server address and port. Here you can also test server status:
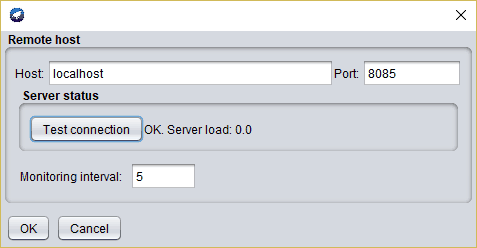
Then click OK to run an algorithm on the server.
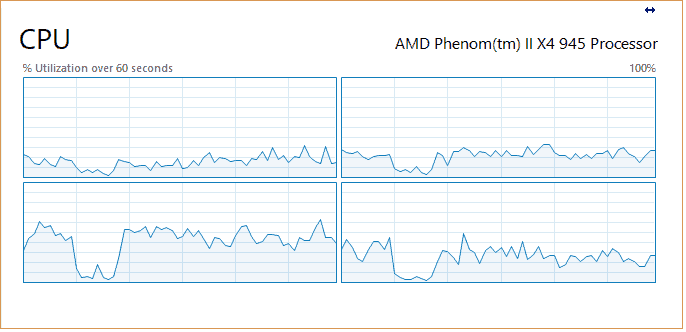
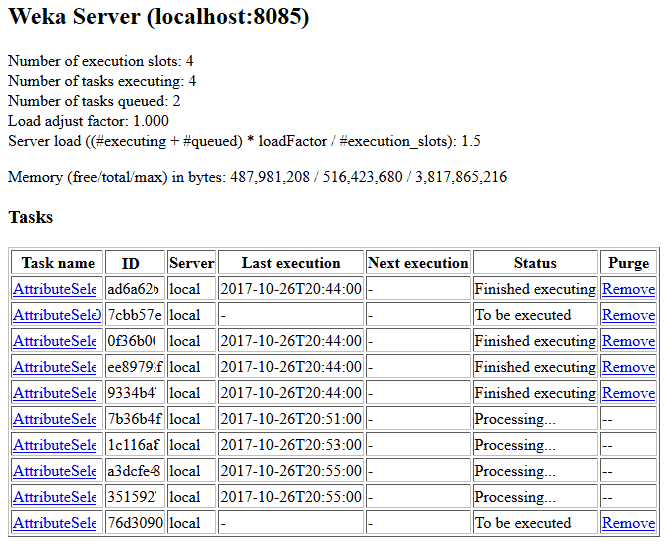
In the web browser, you can see all tasks being executed. Since we have selected four cores, simultaneously, four tasks are executed while other are queued.
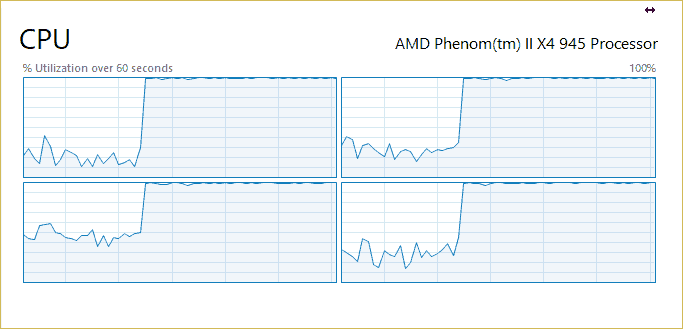
As you can see, all four cores of the processor are utilized at 100%, so the processing is going much faster than on standard run.
For comparison, I have run same classifier locally and on the server. The results are almost two times faster when the server is used:
- Local: 32 s;
Server: 17s;
Of course, this is a small task to compare, but the significance is visible.
WekaServer can be used for remote Knowledge Flow scheduling and monitoring. Logging and status information is retrieved at a user-specified time interval from the server and appears in the UI in the same way as when run locally.
Final Thoughts on Weka Server
OF course, there are some shortcomings when using WekaServer, especially when using more advanced algorithms like Attribute Selected Classifier. You get only classification results on the result window, but selected attributes are not displayed how they are visible on a regular run. As I mentioned, this functionality should be included into weka package as default with Start Server button, so you do not need to run a server locally. I understand the idea that servers can be run on other machine than WEKA GUI, but still, for noobs like me, wanting to utilize all cores of CPU could be beneficial.
Overall WekaServer saves time when performing large classification and complex knowledge flow tasks. This is where multi-core processors like Ryzen or Threadripper might shine.
thank you