
Single feature linear regression is simple. All you need is to find a function that fits training data best. It is also easy to plot data and learning curves. But in reality, regression analysis is based on multiple features. So in most cases, we cannot imagine the multidimensional space where data could be plotted. We need to rely on the methods we use. You must feel comfortable with linear algebra, where matrices and vectors are used. If previously we had one feature (temperature), now we need to introduce more of them. So we need to expand hypothesis to accept more features. From now and later on, instead of output y, we are going to use h(x) notation:

As you can see, with more variables (features), we also end up with more parameters θ that has to be learned. Before we move let’s find relevant data that we could use for building machine learning algorithm.
The data set
Again we are going to use data set college cengage. This time we select health data set with several variables.
The data (X1, X2, X3, X4, X5) are by city.
X1 = death rate per 1000 residents
X2 = doctor availability per 100,000 residents
X3 = hospital availability per 100,000 residents
X4 = annual per capita income in thousands of dollars
X5 = population density people per square mile
Reference: Life In America’s Small Cities, by G.S. Thomas
Here we take variables X2, X3, X4, and X5 as input and X1 as output. And then, we build a linear regression model where we are going to predict death rate per 1000 residents.
Death rate per 1000 residents (y) | Doctor availability per 100,000 residents (x1) | Hospital availability per 100,000 (x2) | Annual per capita income in thousands of dollars (x3) | Population density people per square mile (x4) |
8 | 78 | 284 | 9.100000381 | 109 |
9.300000191 | 68 | 433 | 8.699999809 | 144 |
7.5 | 70 | 739 | 7.199999809 | 113 |
… | … | … | … | … |
There are n = 53 sets of features in this data set.
Linear regression hypothesis
We have four features in each training example and one output, so we will need to find hypothesis:
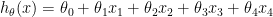
When working with linear algebra we must follow the few notation rules in order to make it easier to follow. So we annotate ith training example  for instance our first training example vector looks like:
for instance our first training example vector looks like:
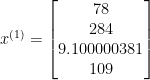
And further, we can annotate jth feature in ith training example 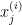 . For instance, from our training set, we can see that two features of 2 training examples are
. For instance, from our training set, we can see that two features of 2 training examples are 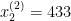 .
.
Since we are using linear algebra, it is convenient to write hypothesis by including x0 variable, which is always equal to 1. So we can write hypothesis h(x) in very compact form:

where

and
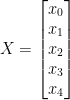
So this is pure linear algebra, and we won’t go deeper into this.
Feature normalization
When building a linear regression model with multiple features, we face another problem. The values of features may differ by orders of magnitude. For instance, Annual per capita income in thousands of dollars (x3) value is about ten while Hospital availability per 100,000 (x2) may reach several hundred. This may influence the gradient descent calculation effectiveness. So we need to scale features to make algorithm converge much faster. The procedure is straightforward:
- Subtract the mean value of each feature from the training set.
- Then additionally, scale (divide) the feature values by their respective standard deviations.
To do this, we can write a pretty simple python algorithm:
def normalization(x):
mean_x = [];
std_x = [];
X_normalized = x;
temp = x.shape[1]
for i in range(temp):
m = np.mean(x[:, i])
s = np.std(x[:, i])
mean_x.append(m)
std_x.append(s)
X_normalized[:, i] = (X_normalized[:, i] - m) / s
return X_normalized, mean_x, std_x
Since we are dealing with multidimensional data, we also need to write vectorized cost and gradient descent functions:
Vectorized Cost function
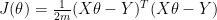
def cost(x,y,theta):
m = y.size #number of training examples
predicted = np.dot(x,theta)
sqErr = (predicted - y)
J = (1.0) / (2 * m) * np.dot(sqErr.T, sqErr)
return J
Vectorized gradient algorithm
Run until converge:

def gradient_descent(x, y, theta, alpha, iterations):
#gradient descent algorithm to find optimal theta values
m = y.size
#theta size
theta_n = theta.size
#cost history
J_theta_log = np.zeros(shape=(iterations+1, 1))
#store initial values in to log
J_theta_log[0, 0] = cost(x, y, theta)
for i in range(iterations):
#split equation in to several parts
predicted = x.dot(theta)
for thetas in range(theta_n):
tmp = x[:,thetas]
tmp.shape = (m,1)
err = (predicted - y) * tmp
theta[thetas][0] = theta[thetas][0] - alpha * (1.0 / m) * err.sum()
J_theta_log[i+1, 0] = cost(x, y, theta)
return theta, J_theta_log
How to know what number of iterations and learning rate alpha to choose? Usually, you should keep an eye on Cost function change during each iteration. We keep cost function values in J_theta_log that can be put on the chart. If everything is selected correctly you should see normal convergence function toward zero:
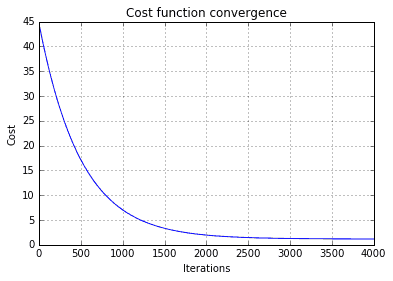
If you see cost increasing or wavy, then try decreasing learning rate parameter alpha (try 0.01, 0.001, and so on). On the other hand, if cost function doesn’t reach flat shape, try an increasing number of iterations. If you see that convergence doesn’t decrease by less than 0.001, you can stop learning and use learned parameters in your regression formula.
Gradient descent algorithm can be improved by implementing automated check on the minimal error; this way it could stop earlier than performing all iterations.
With this record, we are going to finish on linear regression. It is a reasonably fast and straightforward machine-learning method that is used in many areas. It is an ideal solution to b implemented into microcontroller applications where processing power and memory is limited. But in reality, not all data can be fitted with linear models, so there are more advanced methods used like Logistic regression, support vector machines, neural networks, and classifiers. We will take a look at them gradually.
You can download Anaconda project files here (linear_regression_multiple.zip) if you would like to try running a linear regression algorithm by yourself.