
As the name suggests, synthetic data is the data that is artificially generated rather than being created by actual events. In marketing, social media, healthcare, finance, and security, synthetic data helps build more innovative solutions.

Data is the key to resolution and quality service, whether you are processing an invoice or extracting information from a centralized legacy system.
Many organizations complain that collecting and using data raises privacy concerns and leave their business to data breaching issues. Also, some data is tough to collect and incurs a high cost to the organization. For example, collecting data related to real-time events like banking transactions and road events for autonomous vehicles take a heavy load on organization costing.
Then, what’s the solution to collect and use data without breaches, fines, or punishment. The answer is in Synthetic Data. Do you want to know what synthetic data is, why you need it, and how you can make the best use of synthetic data? Let’s get rolled into this blog and learn all about Synthetic data.
What is Synthetic Data?
Synthetic data is annotated information that computer algorithms generate as alternative data. If we put it in a simple form, Synthetic data is created digitally rather than collected or measured manually in the real world.
The significant advancement in the rise of synthetic data is a more data-centric approach to Artificial Intelligence technologies like Machine Learning. As per Gartner’s prediction, “By 2030, most of the data used in AI will be artificially generated by rules statistical methods, simulation or other techniques.”
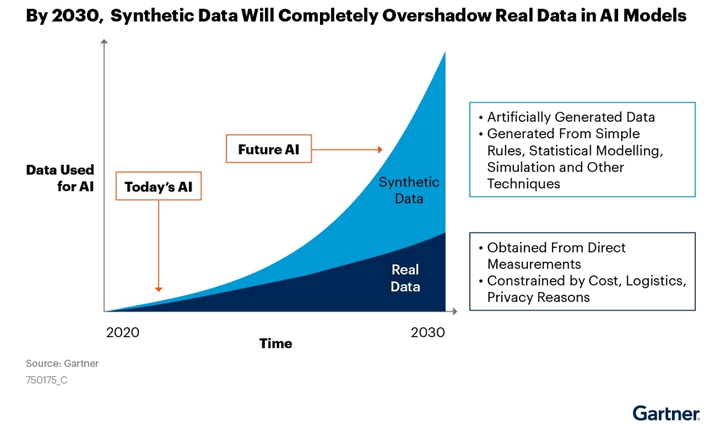
Synthetic Data vs. Real Data
When it comes to using real data, it’s tricky, as real data contain the information that researchers don’t want to disclose as it might lead to data breaches and privacy violations.
But, with synthetic data, privacy is not a concern. Synthetic data ensures-
- Labeled data in a uniform way
- Privacy and confidentiality
- Error-free data
- Data collation from multiple resources
- Existing Data scalability
- Data quality and balance
Why is Synthetic data important?
Most developers need data to create neural networks for machine learning as diverse training datasets create more powerful AI models. But extraction and labeling data contain a few thousand to ten million elements that are time-consuming and expensive. But synthetic data reduce the burden of collecting and labeling millions of data and the cost related to it. Synthetic data ensures that you have the label data with all the diversity to represent in the real world.
Benefits of Synthetic Data
Synthetic data comes with a range of benefits for almost every industry type, from finance to healthcare. The best way it helps an organization is to reduce the need to capture images and data from the real world and make it possible to generate and construct a dataset much more quickly than a dataset that depends on real-time events. Synthetic data has a variety of use cases and can be applied to any machine learning task or process. Some of the typical applications of synthetic data are-
- Automotive
- Robotics
- Finance
- Healthcare
Using synthetic data helps vehicle manufacturers create training data for cars at a real-time pace to avoid accidents and casualties. Also, the banking and finance industry can benefit from synthetic data by creating a fraud detection model for detecting fraudulent transactions and maintaining data security.
In addition, healthcare organizations can leverage synthetic datasets to train AI models for better medical imaging and patient care while protecting patient privacy.
Challenges of Synthetic Data
However, synthetic data comes with a range of benefits but specific challenges that make a tough call for organizations. These challenges include:
- As synthetic data is not the replica of actual data, it might not cover the original data’s outliners.
- Synthetic data might reflect biases in data as the quality of synthetic data is dependent on the quality of input data and data generation model.
- Synthetic data adoption might be slower due to no witness of benefits before.
- It takes huge time and effort to generate synthetic data.
Synthetic Data- Key to unlocking new Possibilities
Compared to real-time data synthetic dataset generation model is much faster, accurate, and time savvy. From allowing data science engineers to train machine learning models to create an autonomous AI, synthetic data has a lot on its plate to drive in this data-centric era.
It’s not only a replacement for real-world data but is much bigger than that. Synthetic data offer data scientists to create innovative solutions that are almost impossible with real data alone. It’s time to pedal for a better world with synthetic data before it’s too late; act Now!
Author Bio

Vatsal Ghiya is a serial entrepreneur with more than 20 years of experience in healthcare AI software and services. He is the CEO and co-founder of Shaip, which enables the on-demand scaling of our platform, processes, and people for companies with the most demanding machine learning and artificial intelligence initiatives.