
In 2011, AlexNet’s achievement on a prominent image classification benchmark brought deep learning into the limelight. It has since produced outstanding success in a variety of fields. Deep learning, in particular, has had a significant impact on computer vision, speech recognition, and natural language processing (NLP), effectively reviving artificial intelligence.
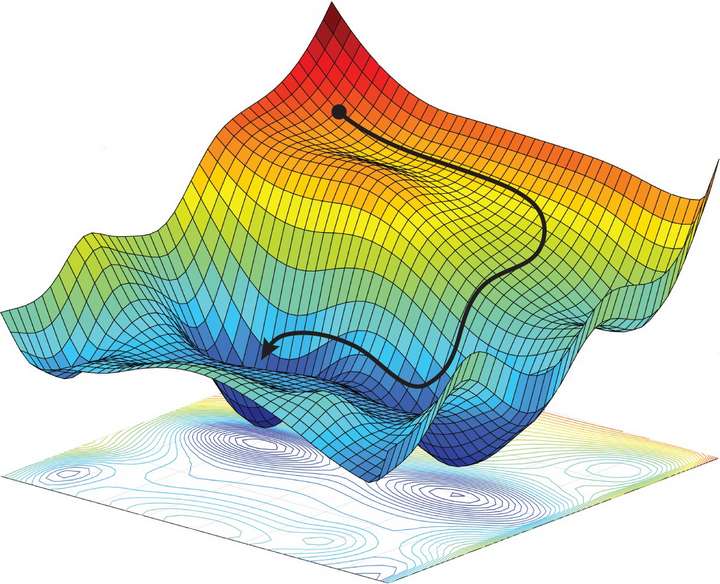
Due to the availability of extensive datasets and good computational resources, Deep Learning has even prospered to a whole new level. Although massive datasets and good computational resources are there, things can still go wrong if we cannot optimize the deep learning models properly. And, most of the time, optimization seems to be the main problem for lousy performance in a deep learning model.
The various factors that come under deep learning optimizations are normalization, regularization, activation functions, weights initialization, and much more. Let’s discuss some of these optimization techniques.
Weights Initialization
Initialization is the first topic to consider while training and optimizing a neural network. It’s an initiation that determines how successfully a subsequent training or learning process will go and how long it will take to complete. For faster convergence and improved network optimization, proper initialization is critical.
Consider a deep neural network whose weights are set at a meager value at the start. As we proceed backward through the layers, their gradient grows smaller. As a result, neurons in the early network layers learn far more slowly than neurons in the later layers.
For that reason, weight updates are insignificant, resulting in the vanishing gradient issue. If the gradients become 0 on the first few levels, they will vanish entirely on subsequent layers. As a result, the first layers, often known as the building blocks, are the most crucial.
Similarly, if we set the weights to a significant number, the gradients in the preceding layers become considerably greater. Large weight updates result, leading weights to expand to infinity (NaN). The problem is known as the bursting gradient problem. As a result, the weights setup is critical.
Normalization
Modeling on real-world datasets is difficult due to their vast ranges and values. Consider a grayscale image in which each pixel may be represented by a value ranging from 0 to 255, with 0 representing black and 255 meaning white.
Even though black and white have equal importance, the machine learning algorithm is dominated by the greater value due to the significant difference in their pixel values. The white pixels are dominating in our grayscale image.
Furthermore, unnormalized data causes the network to become unstable, leading to exploding gradients, slowing down the training process. As a result, getting them all into the same range is critical.
Normalization is the process of transforming each data into the same scale so that each feature is equally relevant. The various normalization techniques include min-max normalization, standardization, batch normalization, layer normalization, etc.
Activation Functions
Activation functions are those that calculate a weighted total and then add bias to it to determine whether a neuron should be activated or not. The activation function aims to induce non-linearity into a neuron’s output.
Without an activation function, a neural network is just a linear regression model. The activation function transforms the input in a non-linear way, allowing it to learn and accomplish increasingly complicated tasks. There are several activation functions, and each of them has its usefulness. Some activation functions are Sigmoid, Tanh, ReLU, Leaky ReLU, etc.
Optimizers
Optimizing a neural network is an extremely challenging task. We aim to train the model to have optimized weights for better predictions in neural networks. For this, we use various optimizers like SGD (Stochastic Gradient Descent), Momentum, RMSprop, Adagrad, Adam, etc. The function of these optimizers is to minimize the loss function optimally.
SGD or stochastic gradient descent is the most commonly used optimizer. SGD employs only first-order information and may even get stuck on local minima. At the same time, Adam is considered the best performing optimizer.
The Adam optimization combines momentum, RMSprop, and learning rate scheduling using Pytorch learning rate scheduler to produce the best optimization results currently available.
However, there is always a slight edge where the performance may vary according to the dataset and architecture. Optimization of a deep learning model is thus a challenging task. Various factors like weights, learning rate, loss functions, amount of data, choice of algorithms, and different hyperparameters play a significant role in its performance. With proper optimization, deep learning models give good results with better accuracy.